


Qu'est-ce que JobRunr ?
JobRunr est une librairie Java OpenSource que vous pouvez ajouter à vos applications pour planifier l'exécution de traitements en arrière-plan.
Cette librairie est relativement jeune puisque les développements n'ont débuté qu'en 2020.
Ronald Dehuysser, le développeur à la genèse de ce projet, voulait un outil simple dans sa mise en place et dans le suivi des traitements exécutés.
Malgré tout, des entreprises de premier plan n'ont pas hésité à l'intégrer dans leurs SI.
J'ai déjà utilisé le scheduler Spring sur différents projets, ainsi que Quartz avec QuartzDesk, mais, lors d'un meetup, ma curiosité a été piquée par l'apparente simplicité proposée par JobRunr.
Aujourd'hui, 3 versions sont proposées : la version OpenSource et gratuite, et deux versions payantes qui permettent d'exécuter beaucoup plus de traitements ou d'accéder à des fonctionnalités avancées.
Installation
Comme je le disais à l'instant, JobrRunr n'est rien de plus qu'une librairie que vous ajoutez aux dépendances de votre application pour planifier l'exécution de vos traitements.
Votre application doit être dans une version au moins égale à Java8, notamment pour bénéficier des lambdas, ce qui ne devrait plus être un problème aujourd'hui, enfin je vous le souhaite.
Grâce à ces lambdas, vous pouvez lancer un traitement qui s'exécute dans un thread dédié, permettant ainsi de libérer le thread courant.
Notez aussi que les dernières versions de JobRunner supportent les virtual threads.
Ajoutez-y quelques lignes de configuration, et un système de stockage (celui de votre application fera l'affaire dans un premier temps), et c'est parti !
Use cases
Ce type d'outil sert généralement pour des traitements qui prennent du temps, ou pour des traitements qui doivent être lancés régulièrement sans intervention extérieure.
Par exemple, l'entreprise Decathlon utilise JobRunner pour gérer les inventaires de ses magasins.
La synchronisation entre le stock physique et le stock numérique est régulière et le volume de données à traiter est relativement important pour nécessiter de longs traitements.
On peut aussi s'en servir pour du traitement d'images qui nécessitent plusieurs étapes, comme le regroupement des médias selon certains critères puis le traitement en tant que tel.
Les temps de traitements peuvent alors être réduits et les outils apportés par JobRunner permettent de pointer d'éventuels goulots d'étranglement ou de prioriser certaines tâches.
Atouts
Si la simplicité est le fil conducteur de JobRunner, nous pouvons cependant noter les avantages suivants :
- Très peu intrusif, avec juste une librairie et quelques lignes de configuration
- Stockage varié, que ce soit des bases SQL, NoSql ou InMemory pour s'amuser
- Horizontal scaling, avec une configuration de base pour gérer la montée en charge
- Dashboard intégré, pour suivre les travaux
Intégration
JobRunner s'intègre parfaitement avec les différents frameworks Java que sont Spring, Quarkus ou encore Micronaut.
Il suffit d'ajouter la librairie dans les dépendances de l'application.
Le format de stockage des jobs est réalisé au format JSON ; il faut donc aussi une librairie pour gérer ce format, comme Jackson.
Vous pouvez alors exécuter votre premier job soit en passant par une lambda, soit en passant par le pattern Command / CommandHandler.
L'usage du pattern nécessite cependant un peu plus de code.
Dernièrement, un builder a fait son apparition pour lancer des jobs avec des paramètres configurables à l'exécution, là où ce n'était pas le cas avec les annotations.
Stockage
Pour stocker les informations sur les jobs, vous aurez besoin d'une base de données.
Par défaut, JobRunner pourra utiliser celle qui est déjà définie dans votre application, mais vous pouvez lui dédier un stockage dédié.
Les principaux acteurs du SQL (PostgreSQL, MySQL, MariaDB, Oracle, SQL Server, DB2, etc) et du NoSQL (ElasticSearch, MongoDB, Redis) sont supportés et les entités nécessaires au fonctionnement de JobRunner seront créées automatiquement au premier démarrage de l'application.
Pour continuer dans la simplicité, JobRunner s'occupe de faire le ménage dans les jobs qui se sont terminés avec succès.
Même s'il existe un délai par défaut, vous avez la possibilité de choisir la durée de rétention de vos anciens traitements.
Cloud
L'architecture de JobRunner a été pensée pour être cloud native et agnostique.
Que ce soit sur AWS, GCP ou encore Azure, pour éviter un engorgement dans l'exécution de vos traitements, il suffit d'augmenter le nombre d'instances de votre application.
Lorsqu'une demande de lancement d'un job est effectuée, sa définition est stockée.
Les autres instances interrogent le stockage et l'une d'entre elles prend en charge l'exécution du traitement.
L'utilisation d'un optimistic lock permet d'éviter que plusieurs instances de l'application n'exécutent le même traitement.
Lorsque le traitement est terminé, ses informations sont mises à jour dans la base.
Gestion des erreurs/monitoring
JobRunner intègre parfaitement la gestion des erreurs avec la mise en place de Retry et Back-off policy, pour retenter un nombre de fois l'exécution d'un traitement qui aurait rencontré un problème.
Mais là où il se démarque vraiment de la concurrence c'est sur l'apport d'un dashboard intégré, (dés)activable grâce à une propriété.
Ce dashboard, accessible depuis un navigateur permet de suivre en temps réel l'exécution des traitements, qu'ils soient planifiés, en cours ou terminés, mais aussi de voir les logs produits en cas d'erreur.
Le dashboard possède aussi des écrans statistiques, sur les durées, les consommations, le nombre de traitements en cours/terminés, etc.
Cas pratique
Pour illustrer la partie théorique, j'ai développé une petite application <span class="css-span">Java</span>/<span class="css-span">Spring Boot</span> qui intègre une image dans une autre image, comme un tableau ou un cadre photo sur un mur.
Vous pouvez retrouver le code sur Github.
Lancer un job
Configurer JobRunr
Rien de plus simple que d'ajouter JobRunr à votre application.
D'abord, ajoutons la dépendance.
Ici, nous sommes sur une application Spring Boot 3.
Avec Maven :
<pre><code><dependency>
<groupId>org.jobrunr</groupId>
<artifactId>jobrunr-spring-boot-3-starter</artifactId> <!-- A adapter selon votre version de Spring Boot -->
<version>7.5.1</version>
</dependency></code></pre>
Ou Gradle :
<pre><code>implementation 'org.jobrunr:jobrunr-spring-boot-3-starter:7.5.1'</code></pre>
Ensuite, passons aux propriétés Spring.
Dans le fichier <span class="css-span">application.yml</span> :
<pre><code>org:
jobrunr:
background-job-server:
enabled: true</code></pre>
Ou, si vous préférez votre configuration dans un fichier <span class="css-span">application.properties</span> :
<pre><code>org.jobrunr.background-job-server.enabled=true</code></pre>
Il y a d'autres propriétés d'autoconfig, mais celle-ci est la seule qui est indispensable pour le moment.
Enfin, choisissons le stockage (<span class="css-span">InMemory</span>) et le mapper (<span class="css-span">Jackson</span>) :
<pre><code>@Configuration
public class JobRunrConfig {
@Bean
public StorageProvider storageProvider() {
InMemoryStorageProvider storageProvider = new InMemoryStorageProvider();
JobMapper jsonMapper = new JobMapper(new JacksonJsonMapper());
storageProvider.setJobMapper(jsonMapper);
return storageProvider;
}
}</code></pre>
Pour faire simple, j'ai utilisé un stockage en mémoire, mais, comme je l'expliquais dans la première partie, il y a de nombreux stockages différents.
Avec cette configuration, nous avons toute l'infrastructure de base pour lancer des jobs.
Exécuter un traitement one-shot
La simplicité d'utilisation impose des contraintes.
Par exemple, si la fonction attend des paramètres, ils doivent être simples.
Comme vous l'avez vu lors de l'instanciation du fournisseur de stockage, le stockage des informations nécessaires au job se fait en JSON.
Les paramètres doivent donc pouvoir être sérialisés et désérialisés dans ce format.
Comme dans mon usecase je manipule des images, j'ai trouvé plus simple de passer par un tableau d'octets.
Ce n'est pas forcément le plus efficace, notamment pour le cache de JobRunr, à cause de la taille du tableau.
Comme amélioration, pour que ce soit justement plus efficace, je pourrais stocker les fichiers et transmettre à JobRunr les noms, chemins ou ID pour permettre le traitement.
C'est d'ailleurs ce qui est conseillé par la documentation.
Pour lancer mon job, j'ai utilisé <span class="css-span">BackgroundJob</span> qui me permet de configurer mon traitement :
<pre><code>BackgroundJob.create(JobBuilder.aJob()
.withId(jobId)
.withName("background-image-processing [" + frameImage.getOriginalFilename() + "]")
.withAmountOfRetries(3)
.withDetails(() -> process(jobId.toString(), imageBytes))
);</code></pre>
Ici, j'ai choisi l'id de mon job, son nom et le nombre de tentatives maximum en cas d'échec (10 par défaut).
La dernière ligne correspond à la méthode qui sera exécutée.
Notez qu'elle doit être <span class="css-span">public</span>, sans quoi JobRunr ne pourra pas l'appeler.
En utilisant une seule méthode supplémentaire, j'aurais pu indiquer à quel moment planifier mon traitement :
<pre><code> .scheduleIn(Duration.ofMinutes(5))</code></pre>
Sans cette personnalisation, j'aurais pu me contenter de la commande suivante :
<pre><code>BackgroundJob.enqueue(() -> process(jobId.toString(), imageBytes));</code></pre>
Exécuter un traitement récurrent
Pour supprimer les images générées depuis un certain temps, j'ai utilisé un autre type de job : les jobs récurrents.
Vous les lancez une fois et ils s'exécutent à fréquence régulière.
Pour changer un peu, j'ai utilisé les annotations fournies par JobRunr :
<pre><code>@Recurring(cron = "0 */5 * * * *")
@Job(name = "Clean old images")
public void submitJobCleaner() {
imageStorage.cleanOldImages();
}</code></pre>
J'aurais pu à nouveau utiliser <span class="css-span">BackgroundJob</span>, notamment pour l'accès aux expressions <span class="css-span">cron</span> toutes prêtes :
<pre><code>BackgroundJob.scheduleRecurrently(Cron.every5minutes(), () -> imageStorage.cleanOldImages());</code></pre>
Etat d'un traitement
Même si vous pouvez voir où en sont vos jobs sur le dashboard, vous pourriez parfois avoir besoin de récupérer les informations depuis votre application.
Dans mon usecase, je voulais remonter les statuts sur mon client web.
Là aussi, c'est plutôt simple.
Il suffit d'accéder au <span class="css-span">StorageProvider</span> configuré au début et de récupérer tous les jobs, ou un seul à partir de son identifiant :
<pre><code>Job job = storageProvider.getJobById(jobUuid);</code></pre>
L'identifiant du job peut être récupéré au moment de sa soumission.
Dashboard intégré
L'activation du dashboard se fait simplement en ajoutant une propriété à l'application :
<pre><code>org:
jobrunr:
dashboard:
enabled: true</code></pre>
Par défaut, il est accessible sur le port 8000 de l'application.
Par exemple : http://localhost:8000
Stats calculées
La page principale expose quelques métriques (RAM, CPU, etc.) et un graphique d'exécution des jobs.
Le tout se met à jour en temps réel.
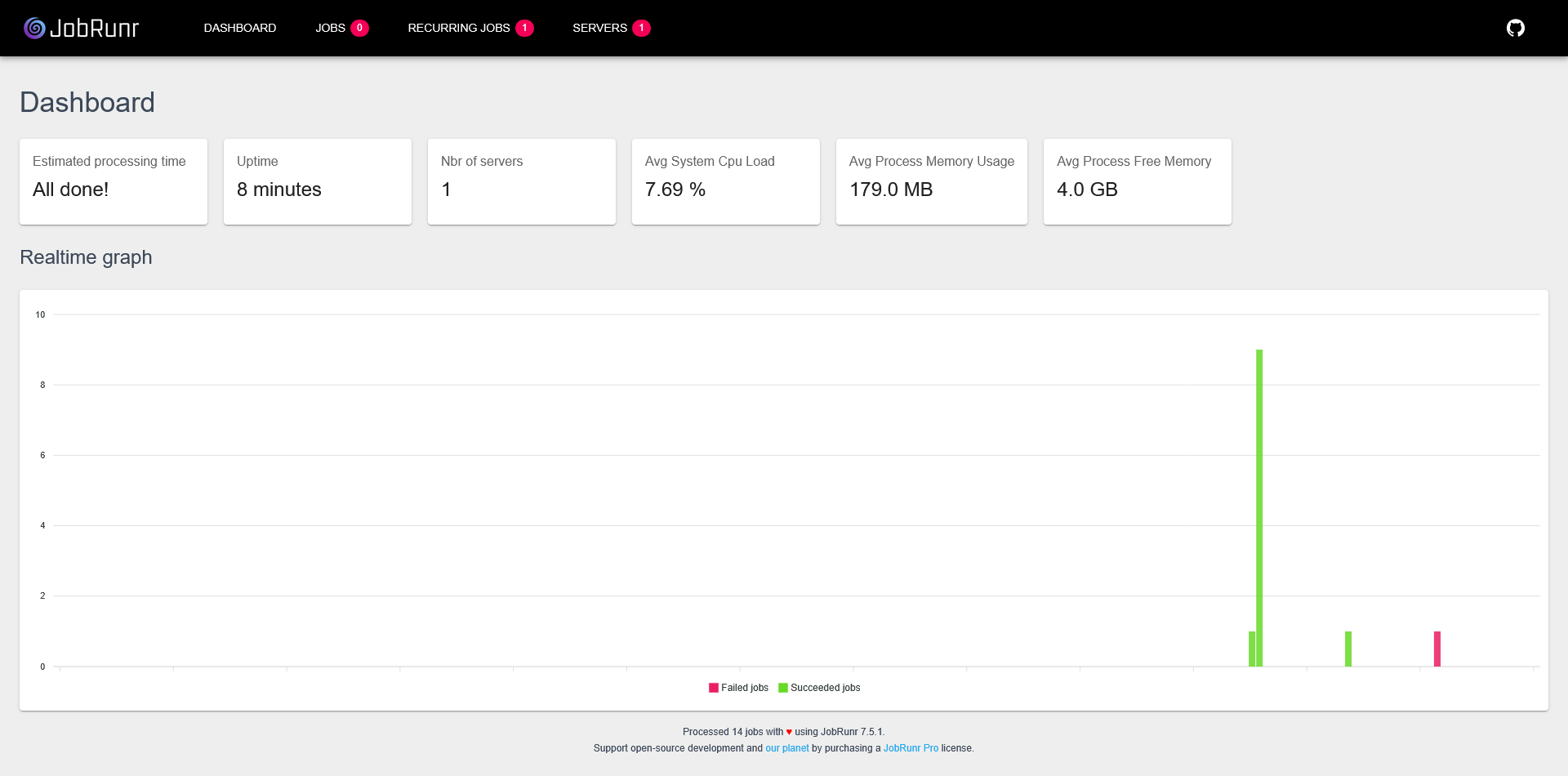
Inspecter
Sur l'écran des jobs, tous les traitements sont regroupés selon leur état d'avancement.

Quelque soit l'avancement d'un traitement, il est possible d'accéder à ses informations.

Nous pouvons noter ici, que toute trace de ce job sera supprimée automatiquement lorsque le temps imparti sera atteint.
Il y a aussi un bouton pour faire cette suppression immédiatement, et il est même possible de relancer le traitement.
Les jobs en erreur
Pour les traitements en erreur, vous pouvez remarquer le nombre de retry effectués.
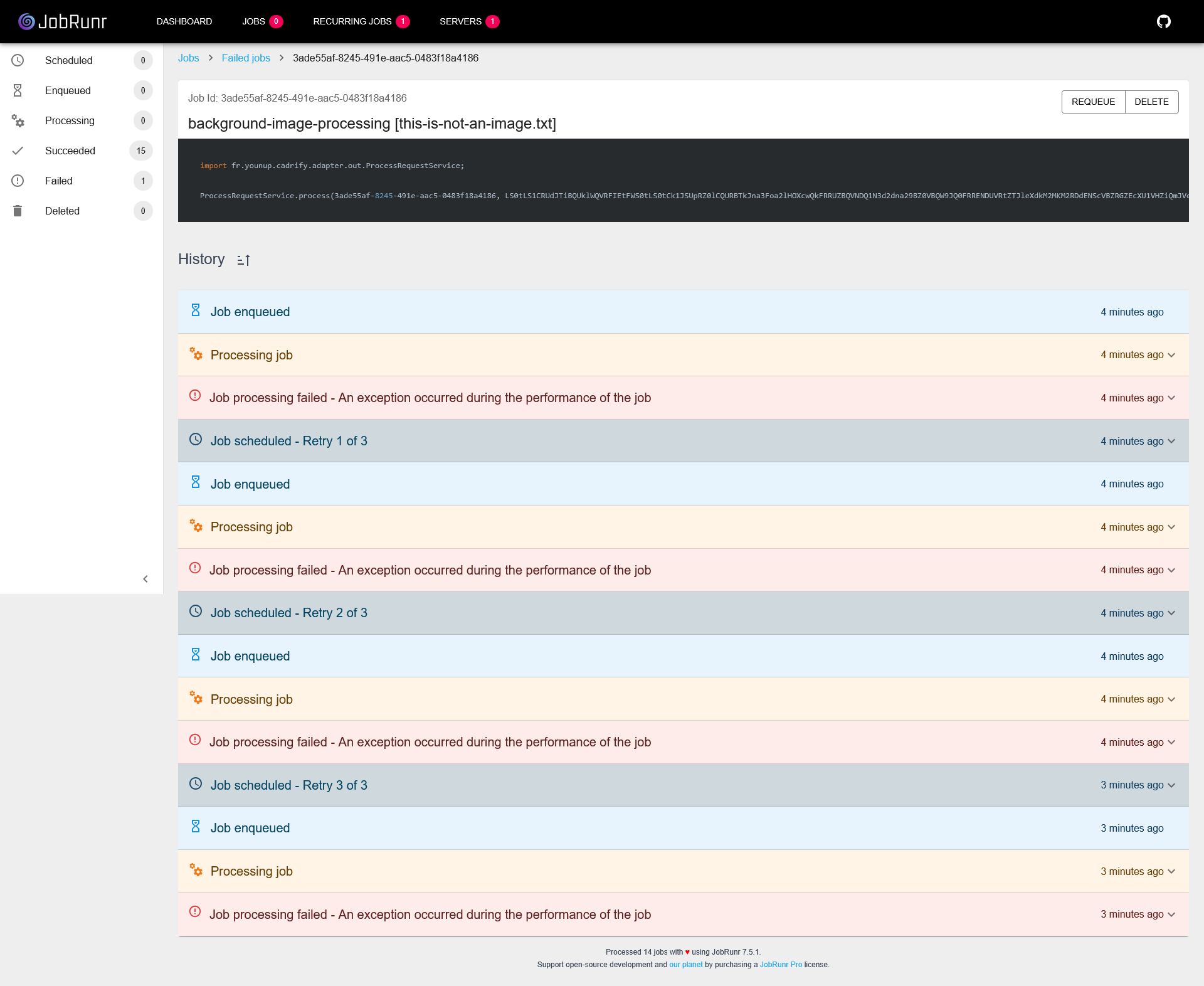
Ici aussi, il est possible de supprimer définitivement le job ou le relancer grâce aux boutons mis à disposition.
Les jobs récurrents
Comme je le disais précédemment, pour faire le ménage dans le stockage des images générées, j'ai mis en place un job récurrent.
C'est sur cet écran qu'on le retrouve.

Avez-vous remarqué que l'expression cron est traduite en langage courant, et qu'on peut voir quand aura lieu le prochain déclenchement ?
Si besoin, vous pouvez effectuer un déclenchement manuel sans avoir à attendre.
Conclusion
Si on fait les comptes, avec une dépendance, deux propriétés, et moins d'une poignée de lignes de code, vous êtes capables d'exécuter des traitements en arrière-plan, et d'en assurer le suivi sur une interface agréable.
En fonction des besoins, ou des habitudes de développement, nous avons pu lancer des traitements de différents types et de différentes manières.
J'apprécie aussi les mises à jour régulières de la libraire.
D'ailleurs, sur le dashboard, vous avez un warning qui vous informe de l'existence d'une nouvelle version.
Parmi ces mises à jour, il y en a une qui concerne l'introduction d'un planificateur carbon aware.
Demain, vos jobs pourront être déclenchés au moment où ils consommeront le moins d'énergies fossiles.
Si vous utilisez la version OpenSource, comme c'est le cas dans mon usecase, vous rencontrerez parfois des limitations.
Avec la version PRO, j'aurais pu récupérer directement mon image produite, sans avoir à passer par un stockage.
Elle permet aussi de gérer des priorités, de mettre en pause des traitements récurrents, de leur donner une date de péremption, ou de gérer les cas de non-déclenchement en cas d'indisponibilité.
Un certain nombre de ces besoins sont contournables avec la version OpenSource, mais ils vous demanderont un peu de développement.
Pour aller plus loin :
- Lien vers le site : JobRunr
- Article sur le carbon aware : blog JobRunr
- Quelques exemples d'applications :
- Dans la documentation : 5 minutes intro
- Sur le repository de JobRunr : Order fulfillment




.svg)

Amoureux du dév depuis toujours, Jean-Yves se souvient, avec presqu'une pointe de nostalgie, des ses premiers programmes en GW/Basic ou en Turbo Pascal !
Aujourd'hui, c'est plutôt en Java qu'il développe mais peu importe le langage, c'est l'évolutivité et la maintenabilité qui lui tiennent à cœur.
Et quand il n'est pas derrière son PC, il est sûrement occupé à cuisiner, à bouquiner ou parti sur les chemins pour préparer une marche Audax.






.svg)

.svg)

.svg)
.svg)